

Architektura pipes and filters, to jeden z wielu wzorców architektonicznych, który można zastosować w swoim systemie. Moduły używające architektury pipes and filters cechują się wysoką elastycznością i możliwością rozbudowy. Rozłóżmy sobie ten wzorzec na czynniki pierwsze i spróbujmy go zaimplementować.
Czym jest architektura pipes and filters?
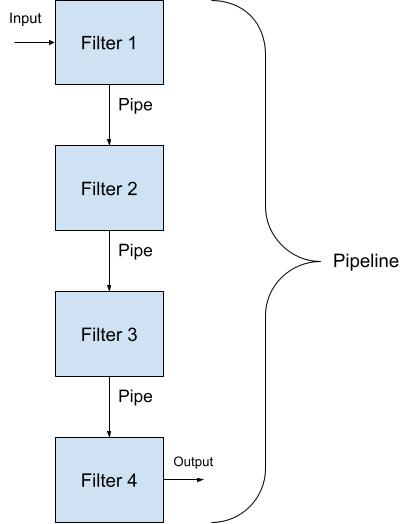
Architektura pipes and filters, to wzorzec architektoniczny, w którym kod podzielony jest na wiele małych i niezależnych fragmentów, określanych filtrami, które komunikują się pomiędzy sobą za pomocą pipes. Pipe, po polsku określamy, jako potok, bądź strumień, więc spolszczona nazwa tego wzorca to architektura filtrów i potoków.
Jego koncepcja opiera się na przekazywaniu danych pomiędzy kolejnymi filtrami, przy pomocy strumieni, pełniących rolę swoistego rodzaju przekaźników. Każdy filtr przetwarza dane na wejściu i przekazuje je na wyjście, gdzie za pomocą potoku przekazywane są do kolejnego filtra. W ten sposób można łączyć filtry w różnych konfiguracjach, tworząc złożone pipeline’y przetwarzania danych.
Skąd się to wzięło?
Wzorzec ten, powstał między innymi dzięki Douglas-owi McIlroy, który wraz ze swoim zespołem zaczął go wdrażać do kodu systemu Unix. McIlroy wprowadził koncepcję potoków, jako mechanizmu przekazywania strumieni danych między procesami, co było kluczowym elementem architektury pipes and filters.
Mechanizm filtrów i potoków w dzisiejszych systemach z rodziny Unix/Linux zna chyba każdy, kto z tymi systemami pracował. Jako użytkownicy najczęściej wykorzystujemy go w konsoli poleceń. Przykładowo chcąc zidentyfikować wszystkie procesy, które w swojej nazwie mają „ssh”, możemy posłużyć się poniższym poleceniem:
ps -ax | grep sshMamy tutaj dwa filtry, pierwszy to ps -ax, który pobiera wszystkie aktualnie działające procesy, następnie za pomocą pipe’a przekazujemy wynik pierwszej operacji do drugiego filtru, który ma za zadanie wybrać tylko te elementy, które zawierają „ssh”. Prawda, że intuicyjne?
Architektura pipes and filters, kiedy się nada, a kiedy nie?
Jak to z każdym wzorcem bywa, tak i ten ma swoje wady i zalety. Do jednego typu rozwiązań nada się znakomicie, a do innego nie. Niemniej jednak, zastosuj ten wzorzec, jeśli Twoje procesy aplikacyjne mogą być łatwo sprowadzone do niezależnych od siebie kroków, a Ty potrzebujesz możliwości łatwej rozbudowy systemu i wymienialności jego elementów. Wykluwa nam się więc trzy główne zalety tego podejścia:
- Modularyzacja: podział kodu na filtry, pipe’y i pipeline’y.
- Łatwość rozszerzania: można dodawać nowe filtry do pipeline’ów nie ingerując w istniejący kod.
- Testowalność: każdy z filtrów może być testowany niezależnie, a dodatkowo, jeśli będziemy chcieli przetestować cały pipeline’y, to łatwo podmienimy filtr dotykający I/O.
Architektura pipes and filters ma też kilka wad. Najważniejszymi do przeanalizowania przed jej zastosowanie są trzy poniższe:
- Overhead komunikacyjny: długie pipeline’y, które operują na dużej ilości danych mogą być problematyczne, gdyż te dane muszą być przekazywane od filtru do filtru.
- Zarządzanie stanem: jeśli Twój filtr musi przechowywać jakiś stan lub bazować na stanie innego filtru, to podejście pipes & filters prawdopodobnie nie jest dla Ciebie, gdyż filtry w zamyśle mają być małe i niezależne od siebie.
- Opóźnienia w dużych pipeline’ach: w synchronicznych pipeline’ach mogą występować bottleneck-i, gdyż długie przetwarzanie przez jeden filtr może zablokować cały proces, bo kolejne filtry czekają na wynik z poprzednich.
Przykład
Wyobraźmy sobie, że musimy zaimplementować moduł do publikacji komentarzy w zewnętrznym systemie. Każdy komentarz powinien być ocenzurowany pod kątem słów niecenzuralnych oraz na życzenie użytkownika możemy automatycznie poprawić gramatykę i interpunkcję, a na sam koniec musimy wywołać REST API endpoint, aby wykonać publikację w zewnętrznym serwisie. Całość brzmi, jak filtry i potoki, zatem do dzieła!
Struktura plików i folderów takiego modułu może wyglądać następująco:
src/
│ ├── publication/
│ │ ├── filters/
│ │ │ ├── censorship.filter.ts
│ │ │ ├── punctuation.filter.ts
│ │ │ ├── publication.filter.ts
│ │ ├── pipelines/
│ │ │ ├── publication.pipeline.ts
│ │ ├── dto/
│ │ │ ├── publication.dto.ts
│ │ ├── controllers/
│ │ │ ├── publication.handler.tsNasze zapytanie zacznie się w kontrolerze, który uruchomi odpowiedni pipeline, a następnie zwróci rezultat działania logiki w nim zawartej. Równie dobrze może to być handler, router, akcja, bądź cokolwiek innego, co w Twojej technologii jest używane do takich rzeczy. Spotkałem się również z podejściem, gdzie pipeline jest bezpośrednio handle-rem akcji rest. Ma on wtedy dodatkowe filtry, np. do walidacji czy autoryzacji.
@Controller('publications')
export class PublicationController {
constructor(
private readonly publicationPipeline: PublicationPipeline,
) { }
@Post()
async publish(
@Body() dto: PublicationDTO,
): Promise<ApiResult> {
const result = this.publicationPipeline.execute(dto);
return ApiResult.from(result);
}
}W kwestii samego pipeline’a, to ma on za zadanie uruchomić filtry, które wchodzą w jego skład. Możemy dodać tutaj obsługę wyjątków, a także zdefiniować inne rodzaje przetwarzania, np. asynchroniczne.
export class PublicationPipeline implements SyncPipeline {
constructor(
private readonly filters: Filter[] = [new CensorshipFilter, new PunctationFilter, new PublicationFilter]
) { }
execute(dto: PublicationDto): Result {
try {
this.filters.reduce((result: Result, filter: Filter) => filter.process(), dto);
return Result.ok();
} catch (error: Error) {
return Result.fail('Publication failed.');
}
}
}I na sam koniec zaimplementujmy jeden z filtrów. Niech będzie to PublicationFilter, który może przyjąć poniższą postać.
export class PublicationFilter implements Filter {
constructor(
private readonly cmsClient: CMSClient
) { }
process(dto: PublicationDto): Result {
const author = this.cmsClient.resolveAuthorByEmail(dto.email);
if (!author || author.blocked) {
throw new RuntimeException('Selected email is not allowed to publish comment.');
}
this.cmsClient.publish({
authorId: author.id,
content: dto.content
});
}
}Oczywiście to, jak atomowe filtry będą zależy wyłącznie od nas. Trzeba pamiętać, aby nie przesadzić w żadną ze stron.
Kolekcja
Bardziej przyziemnym przykładem tego wzorca będzie użycie go w scope’ie niearchitektonicznym. Przecież procesowanie kolekcji danych przy użyciu funkcji wyższego rzędu, to także przykład filtrów i potoków. Każde użycie funkcji jest filtrem, który realizuje pewną logikę akceptując dane na wyjściu i zwracając rezultat, jako wejście do kolejnego filtru. Trzeba tylko pamiętać, aby nie złamać Prawa Demeter i nie opuścić bazowego typu w trakcie przetwarzania.
const numbers = [1, 2, 3, 4, 5];
const filterEvenNumbers = (number) => number % 2 === 0;
const squareNumber = (number) => number * number;
const processedNumbers = numbers
.filter(filterEvenNumbers)
.map(squareNumber);
Podsumowanie
- Architektura pipes and filters, to architektura aplikacyjna, której można używać w swoich modułach.
- Cechuje się wysoką modularnością, otwartością na rozbudowę i łatwością testowania.
- Zastosuj ją, jeśli Twoje procesy aplikacyjne mogą być łatwo sprowadzone do niezależnych od siebie kroków.
Dodaj komentarz